Minimum KL Maximum entropy
In the previous chapter, we saw what happens when we minimize in the KL divergence . We used this to find the best model of data .
In this chapter, we will ponder the second question - what happens if we minimize in ? This way, we will build the so-called maximum entropy principle that guides us whenever we want to choose a good model distribuiton.
Max-entropy principle constructs the most generic distributions satifying some constraints. Most useful distributions are max-entropy for some parameter.
Conditioning on steroids
Suppose I want to determine a probability distribution modelling the random variable of how long it takes me to eat lunch. My initial (and very crude) model of might be a uniform distribution between and minutes.
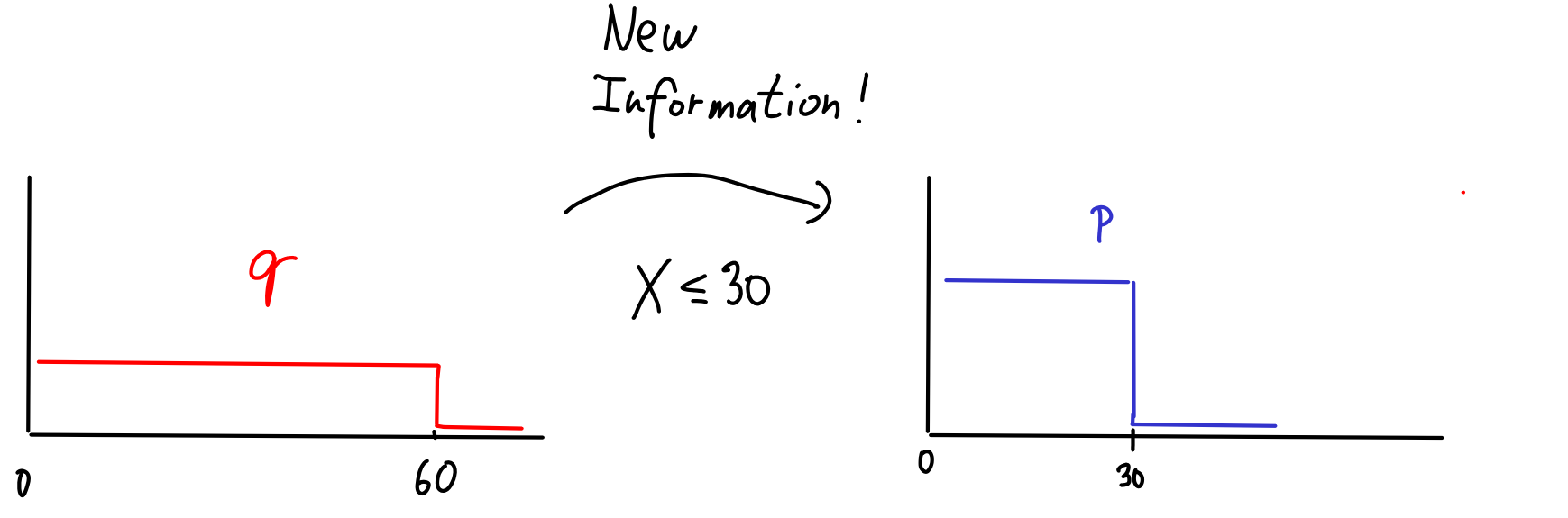
Starting with this model, I can try to get some new information and condition on it to get a better model .
For example, let's say that after eating many lunches, I observe that I always finish after at most 30 minutes. I can turn this to a new information that . I can condition on this information and get a better model:
Let's try again. I eat many more lunches, but this time I keep recording the average time it takes me to eat lunch. Say, it turns out to be 15 minutes. How do I change to reflect this new information? The probability theory gives a clear answer.
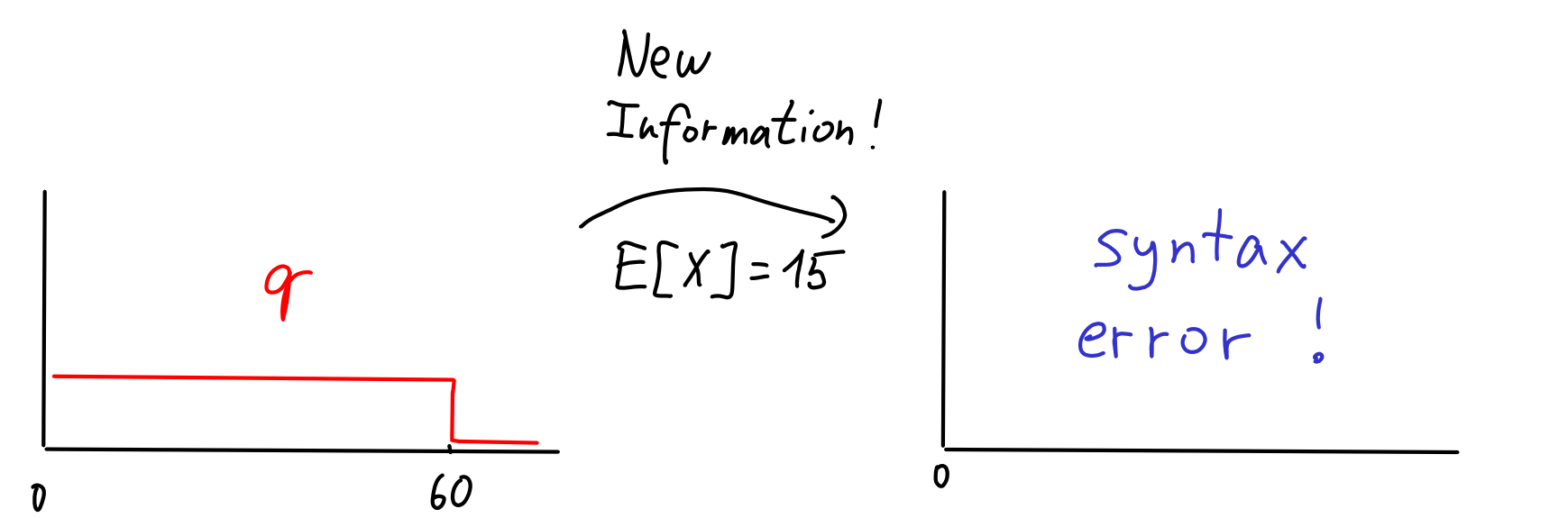
We simply can't do this. In probability theory, we can condition on events like , i.e., facts that are true for some values that can attend, but not others. But now we would like to condition on which is not an event, just a fact that's true for some distributions over , but not others.
The fun part is that we can use KL divergence to 'condition' on . It turns out that the most reasonable way to account for the new information is to choose as the model minimizing KL divergence to . That is, for the set of distributions with , choose
In the example, happens to look like exponential distribution:
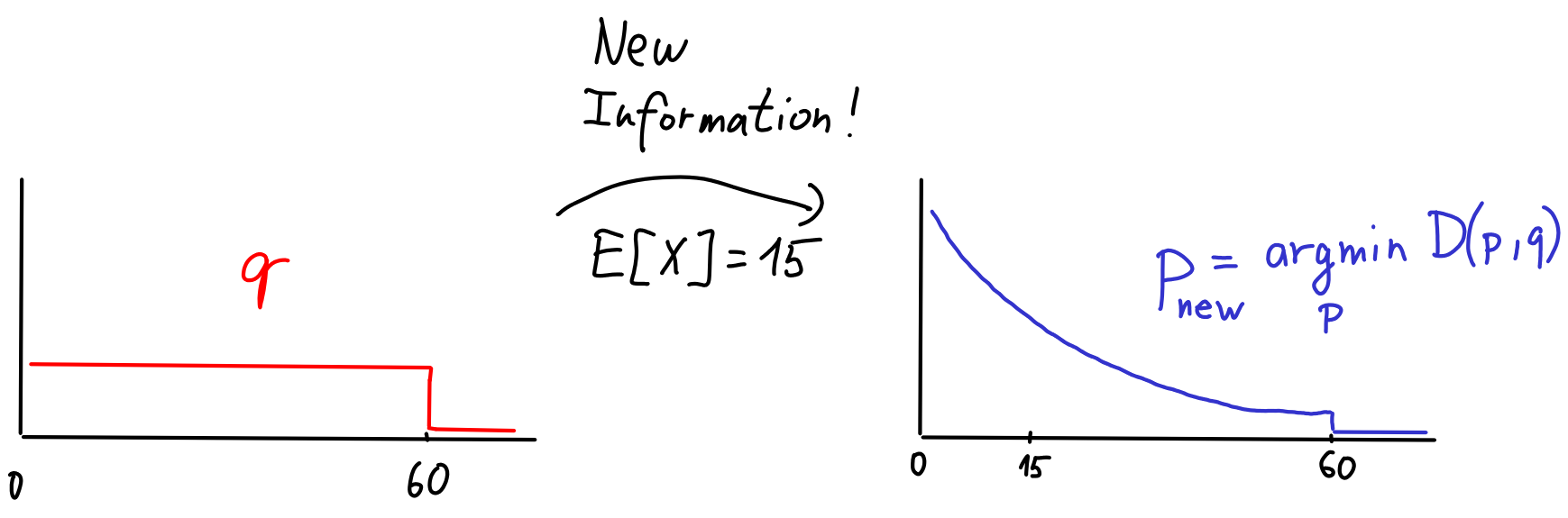
This is sometimes called the minimum relative entropy principle. Why does this make sense? Intuitively, I want to find a distribution that would serve as the new best guess for what the truth is, while the old model distribution remains as good a model of as possible. This is what we achieve by minimizing KL divergence .
Admittedly, this intuition may feel a bit shaky, as we typically prefer to represent the "true" distribution when using KL divergence, whereas here it's simply a new, improved, model. There's a more technical argument called Wallis derivation that explains why we can derive minimum relative entropy as "conditioning on steroids" from the first principles.
The maximum entropy principle
Let's delve deeper into the minimum relative entropy principle. A conceptual issue with it is that it only allows us to refine an existing model into a better model . But how did we choose the initial model in the first place? It feels a bit like a chicken-and-egg dilemma.
Fortunately, there's usually a very natural choice for the simplest possible model : the uniform distribution. This is the unique most 'even' distribution that assigns the same probability to every possible outcome. There's also a fancy name for using the uniform distribution as the safe-haven model in the absence of any relevant evidence: the principle of indifference.
It would be highly interesting to understand what happens when we combine both principles together. That is, say that we start with the uniform distribution (say it's uniform over the set ). What happens if we find a better model by minimizing KL divergence? Let's write it out:
I am a one-trick pony, whenever I see KL divergence, I split it into cross-entropy and entropy:
In the previous chapter, it was the second term that was constant, now it's the first term: does not depend on , so minimizing KL divergence is equivalent to minimizing . We get:
We've just derived what's known as the maximum entropy principle: given a set of distributions to choose from, we should opt for the that maximizes the entropy .
General form of maximum entropy distributions
Let's now dive a bit deeper into maximum entropy. We'll try to understand what maximum entropy distributions actually look like. For example, we will see soon how does the maximum entropy distribution with looks like.
Here's what I want you to focus on, though. Let's not worry about concrete numbers like 15 too much. To get the most out of the max-entropy principle, we have to think about the questions a bit more abstractly, more like: _If I fix the value of , what shape will the max-entropy distribution have?
For such a broad question, the answer turns out to be surprisingly straightforward! Before telling you the general answer, let's see a couple of examples.
If we consider distributions with a fixed expectation (and the domain is non-negative real numbers), the maximum entropy distribution is the exponential distribution. This distribution has the form . Here, is a parameter - fixing to attain different values leads to different s. 1
Another example: If we fix the values of both and , the maximum entropy distribution is the normal distribution, where To keep things clean, we can rewrite its shape as for some parameters that have to be worked out from what values we fix and to.
Spot a pattern?
Suppose we have a set of constraints . Then, among all distributions that satisfy these constraints, the distribution with maximum entropy (if it exists) has the following shape:
for some constants .
Notice that this general recipe doesn't tell us the exact values of . Those depend on the specific values of , while the general shape remains the same regardless of the values. But don't get too hung up on the s and s. The key takeaway is that the maximum entropy distribution looks like an exponential, with the "stuff we care about" in the exponent.
Try building your own maximum entropy distribution on the interval by playing with values:
Maximum Entropy Distribution Builder
Computed Expectations
Why?
Let's build some intuition for this. Remember from the previous chapter that the max-entropy principle is essentially about finding a distribution that is as close to uniform as possible, in the sense of minimizing KL divergence.
So, in what way are max-entropy distributions "close" to being uniform? Let's use the exponential distribution as an example. Say I independently sample two numbers from it, and . Here's a little riddle: Is it more probable that I sample or that I sample ?
The answer is that both options have the same probability density. That's because . In our riddle, , so both possibilities have a density proportional to .
You can test it in the following widget.
This property isn't exclusive to the exponential distribution; it holds for all max-entropy distributions that fit the form given by our formula [Eq. max-entropy-form?]. If you dare, the widget above also visualizes that if you sample from a Gaussian and fix the values of and , the curve this defines (a circle) has constant density.
Maximum Entropy Distribution Visualization
In general, consider a distribution of the shape . Now, imagine independently sampling a few points from that distribution. If you then tell me the values of the averages , and I condition on this information, the conditional distribution over is actually uniform! This is because the probability density of any such tuple under our distribution is the same, equal to
You can imagine this as a generalization of the widget above. There's a super complicated space of all possible outcomes I can get by sampling times from my distribution. The max-entropy property says that if I draw a "contour" through outcomes that share the same empirical averages of the functions , the conditional distribution is uniform on this contour.
So, what's the takeaway? When you sample from max-entropy distributions, the experience is actually quite similar to sampling from a uniform distribution - the distribution over outcomes is uniform once you condition on the value of relevant properties! 2
Catalogue of examples
Let's go through the list of maximum-entropy distributions you might have encountered. In fact, most distributions used in practice are maximum entropy distributions for some specific choice of functions .
So, when you come across a distribution, the right question isn't really "Is this a max entropy distribution?" It's more like, "For what parameters is this a max entropy distribution?" For example, you can forget the exact formula for the Gaussian distribution—it's enough to remember that using it implies you believe the mean and variance are the most important parameters to consider.
Let's go through the examples with this in mind. Please, do skip whatever doesn't ring a bell, the list is long.
Let's start with what happens if we don't have any constraints.
Logits, softmax, exponentials
If we believe the mean is an important parameter of a distribution (which is very typical), the max entropy principle states that the right family of distributions to work with are those with the shape:
This kind of distribution is known by many names, depending on its domain. Let's go through some instances!
🔔 Gaussians
If we fix both mean and variance, the max-entropy distribution is Gaussian.
We can now revisit our financial mathematics riddle from the intro.
Power-law
If you care about the scale of a random variable, maximum entropy leads to so-called power-law distributions.
And here's an application to our XKCD riddle:
🔢 Other Examples
A few more advanced examples, you probably want to skip them.
What's next?
In the next chapter, we'll see how the combo of maximum likelihood + maximum entropy explains the choice of loss functions used in machine learning.